近期,查了下自己网站的配置,发现一个问题。你的网站可能也中招了,自查方法在下面。
一、先说下背景
Cloudflare 是全球最大的网站托管和加速服务商之一,大量独立开发者和中小网站都跑在它上面。
2025 年 7 月,它做了一个影响深远的决定:新接入的网站,AI 爬虫从"默认放行"改成"默认管控"。
现在你往 Cloudflare 上加一个域名,表单里会出现一块"管理 AI 自动程序访问":三个下拉选项(搜索、代理、训练),下面还藏着一个不起眼的小开关。
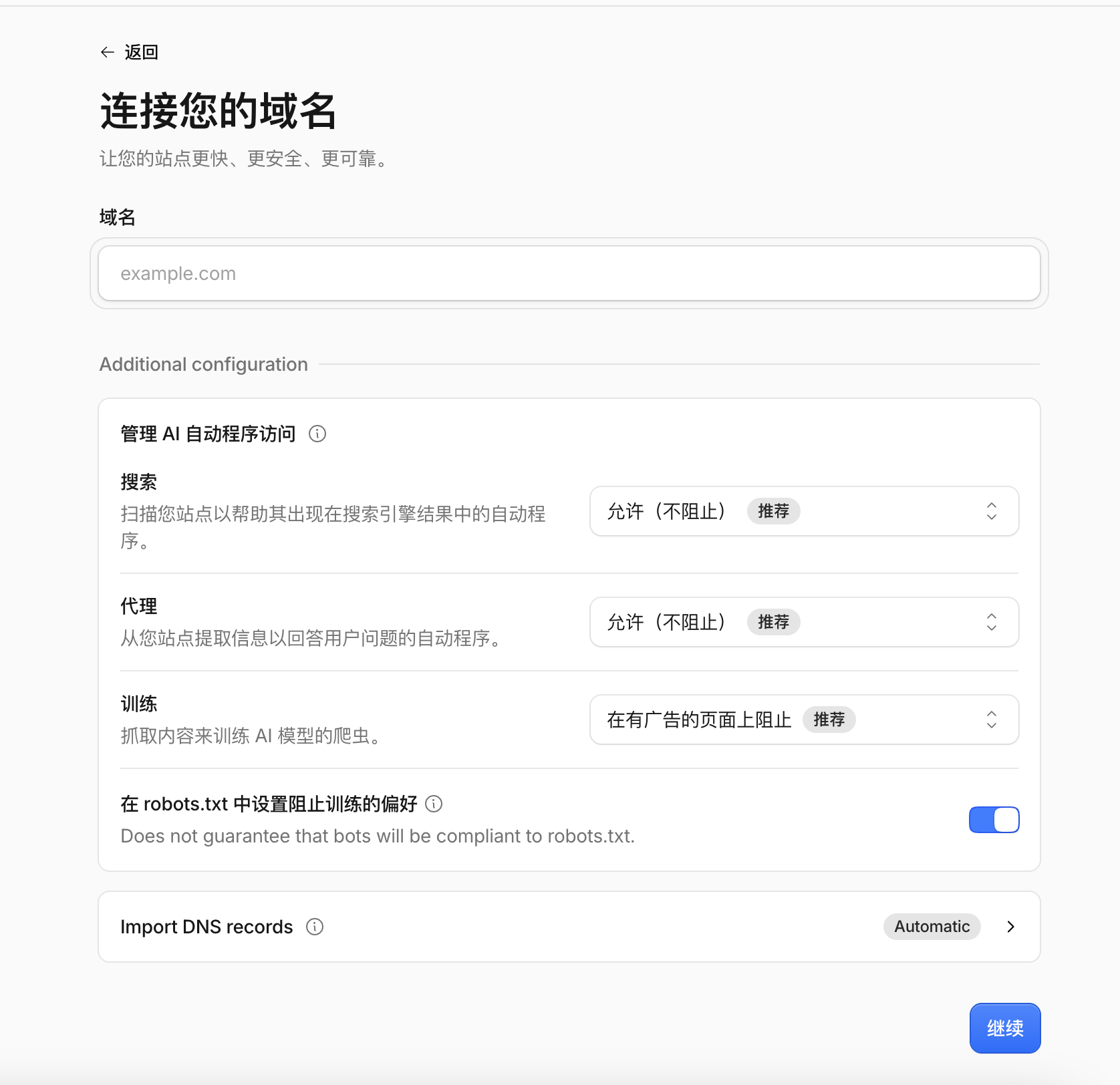
绝大多数人的操作和我一样:保持默认,下一步,部署上线,睡觉。
坑,就埋在那个默认开着的小开关里。
二、三个完全不同的角色
要看懂这个坑,得先分清 AI 爬虫的三种身份。用图书馆打个比方:
搜索爬虫是图书管理员:它把你的网站编进目录,方便别人搜到你。这是老朋友了,Google 干了二十年。
AI 代理是读者:有人问 ChatGPT"某某工具好不好用",AI 现场跑来翻你的网页,引用你的内容回答问题。这是新时代的流量入口。
训练爬虫是学生:它把你的内容"背下来",内化成下一代大模型的知识。今天被它学走的内容,明天就是新模型脑子里"天生就知道"的东西。
三个下拉的默认值其实问题不大:搜索放行、代理放行、训练只在有广告的页面拦截——没广告的站等于不拦。
真正的问题是第四项:“在 robots.txt 中设置阻止训练的偏好”,默认开启。
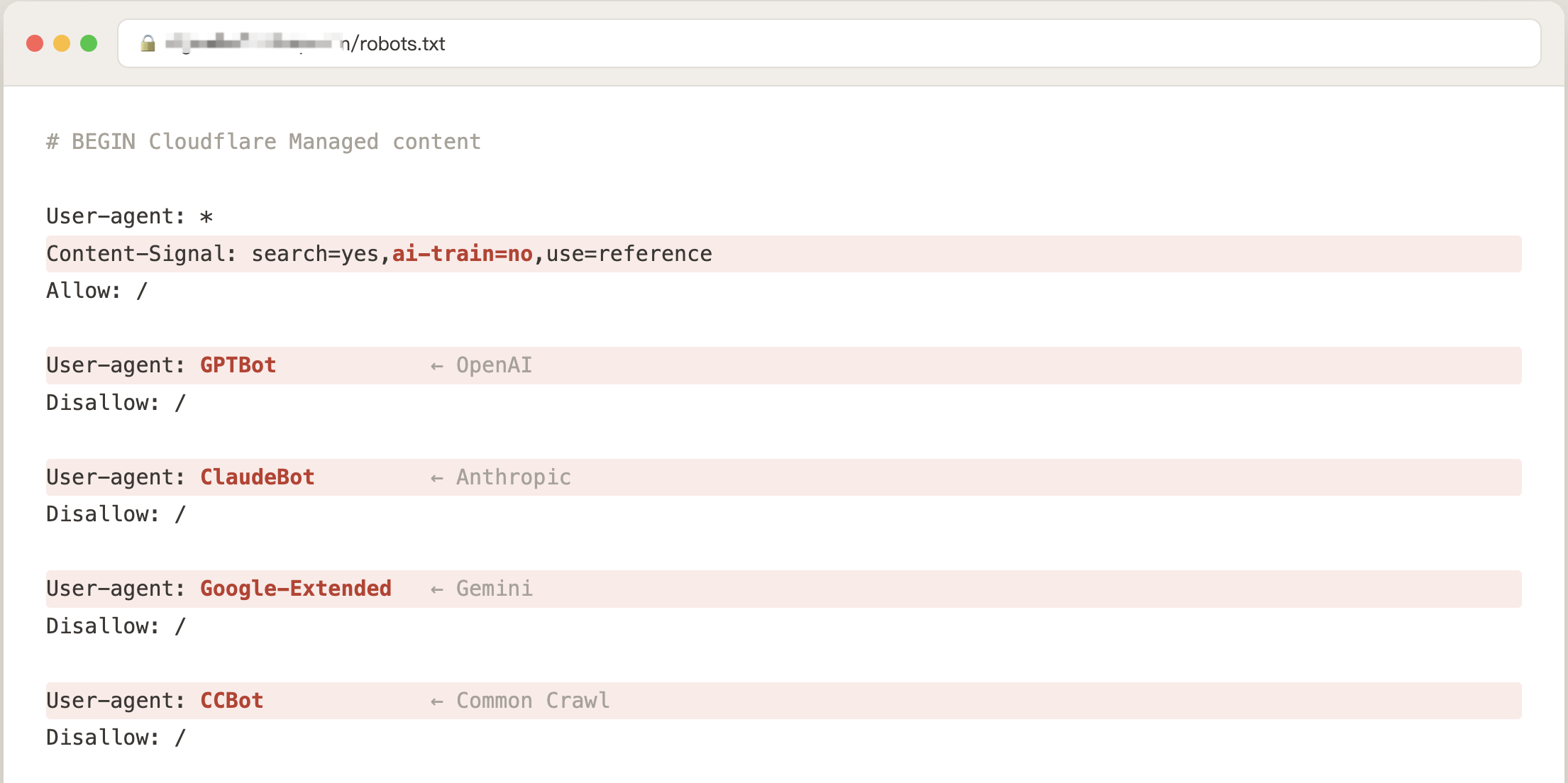
开着它,Cloudflare 会往你的 robots.txt 里注入一份黑名单:OpenAI 的 GPTBot、Anthropic 的 ClaudeBot、Google 的 Gemini 训练爬虫、喂养大量开源模型的 CCBot——全站禁入。
三、爬虫还在来,你以为没事
我一开始也怀疑:后台明明显示 AI 爬虫天天来访问,说明没被挡啊?
这正是这个坑最阴险的地方:爬虫来了,不等于内容会被学走。
robots.txt 里那句 ai-train=no,翻译成人话是:“你可以来看,但不许背下来。”
OpenAI、Google、Anthropic 这些大厂的训练管线,都会遵守这个声明——抓回去的内容,在进训练集之前就被过滤掉了。
结果就是一种温水煮青蛙的状态:AI 搜索今天还能引用你(短期没事),但明年、后年发布的新模型,“天生"就不认识你(长期出局)。
四、Cloudflare 自己都"承认"了
更有意思的是那个开关下面的一行英文小字:
Does not guarantee that bots will be compliant to robots.txt.
翻译:不保证爬虫会听话。
细品一下这意味着什么——robots.txt 只是一块告示牌,不是一堵墙。
守规矩的大厂看到告示牌就真不进来了;不守规矩的野爬虫呢?照爬不误。
也就是说,这个开关开着,最坏的情况是两头亏:挡住了你最想被"记住"的大厂模型,挡不住你真正想防的内容小偷。
五、该拦还是该放?
默认管控不是坏事,Cloudflare 的出发点是保护内容创作者。
关键是这个决定应该由你自己做,而不是稀里糊涂跟着默认走。
判断标准就一条——你的内容是资产,还是获客工具?
内容本身是卖钱的(付费课程、独家研报、原创小说):保持拦截,完全正确。凭什么免费给大模型当教材?
网站是用来被发现的(营销站、博客、产品官网、工具站):赶紧去把开关关了。
六、30 秒自查
- 浏览器打开:你的域名/robots.txt
- 页面里搜两个词:ai-train 和 GPTBot
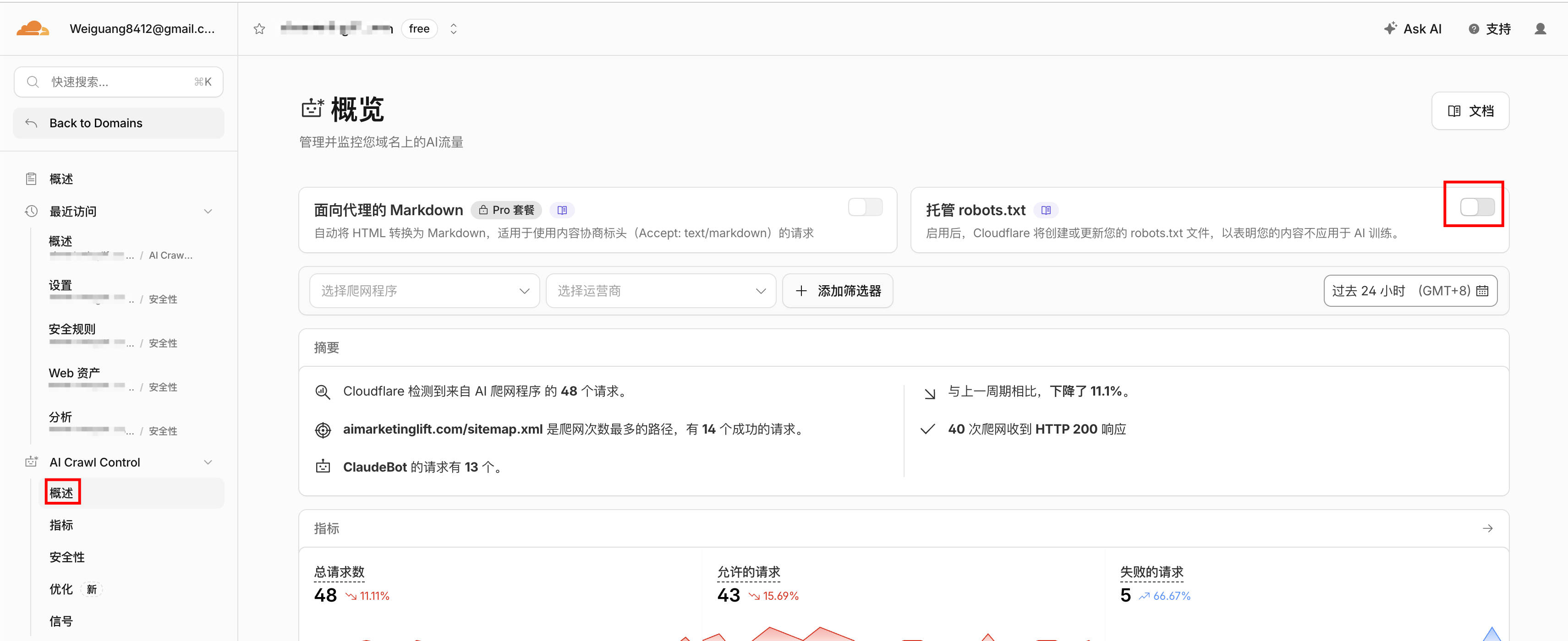
- 如果看到 ai-train=no,或者 GPTBot 后面跟着 Disallow: /,而你的网站是获客用的——去 Cloudflare 后台 → 选中你的域名 → AI Crawl Control → 把"托管 robots.txt"关掉
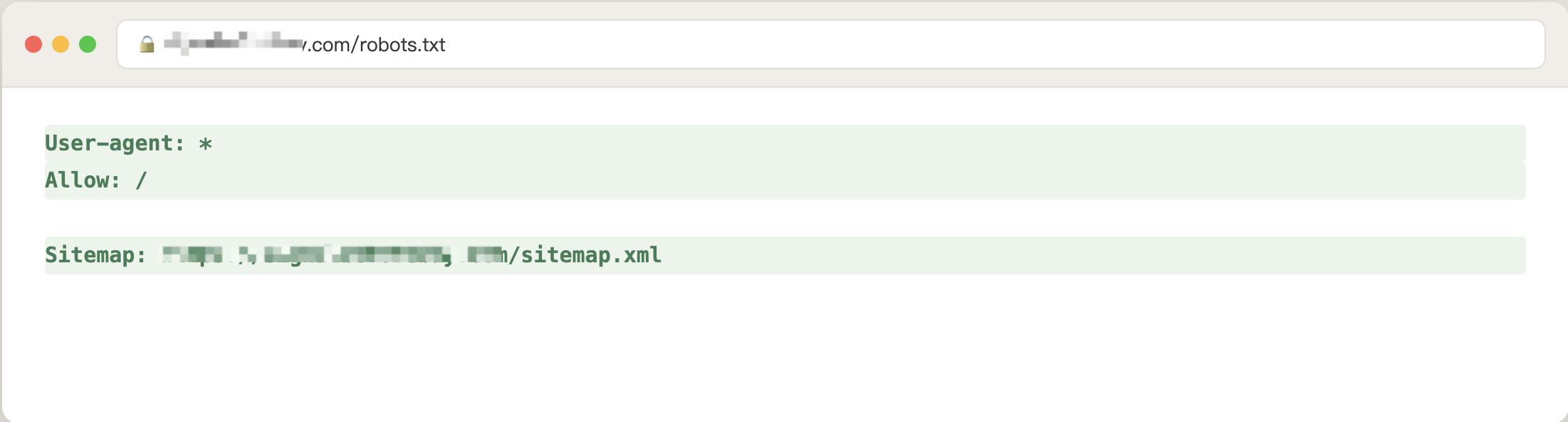
- 关完再刷新一遍 robots.txt,确认那段注入的内容消失了
整个过程不超过一分钟。
总结
过去二十年,网站的生死线是 Google 排名。
接下来十年,可能是另一个问题:当用户直接问 AI"该买哪个、该用哪个"的时候,模型的记忆里有没有你?